比赛概况
这次比赛是真正意义上的第一次参与算法大赛。虽然之前也有报过名,但要不是无任何时间期限的新手练习赛,就是取个数据集随便做做就完事的。这次却是跟两个同样新手的队友组的队一起认认真真的打。
比赛成绩不算很好也不算太差。两千多支队伍,最后初赛第8,复赛17。本来复赛B榜第一天排名第6的,让我们都兴奋了好一阵,然而那天改了一晚上的模型第二天并没有提升,反倒被后面升上来的一堆队伍差点挤出第一页。可惜归可惜,但个人觉得也确实是实力如此。每次改模型都有种无力感,总感觉以前看多少的理论基础都融不进实践当中。明明感觉能更好的模型却反常的更差,调参提特征大半靠玄学。
前路漫漫,所以还是老老实实记录下这次的比赛过程吧。
题目简介:
本次赛题需要选手利用历史某3年的汽车日上牌数据,预测某2年每天的汽车上牌数。初赛将挑选出5个汽车品牌,给出这些品牌每天的上牌数,当天是星期几,来预测5个汽车品牌未来每天的上牌总数。复赛将挑选出10个汽车品牌,仍旧给出品牌每天的上牌数,当天是星期几,来预测10个汽车品牌未来每天的上牌数。
训练数据:

初赛提交结果:

复赛提交结果:
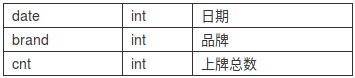
评判标准:均方误差
模型思路
感谢Linus,感谢git帮我能随时回顾比赛期间每一个阶段的模型
初赛阶段
最初的模型
按照以前做练习的习惯,拿到数据集后首先分析数据集情况:
总共是4773条训练数据,5个品牌,其中日期字段脱敏为序数值,无字段有空缺数据
由于初赛仅要求预测5个品牌的上牌量总数,并不区分具体品牌。而训练集除了提供品牌id外,并没有其他任何与品牌有关的字段信息。因此品牌字段暂时被我忽略,直接用pivot_table统计出每一天的上牌量总数。随后就是重中之重的day_of_week字段,大致扫一眼,这个字段的值还是比较连续的,中间只有个别缺失值,其中星期日的数据缺的相对多些点。
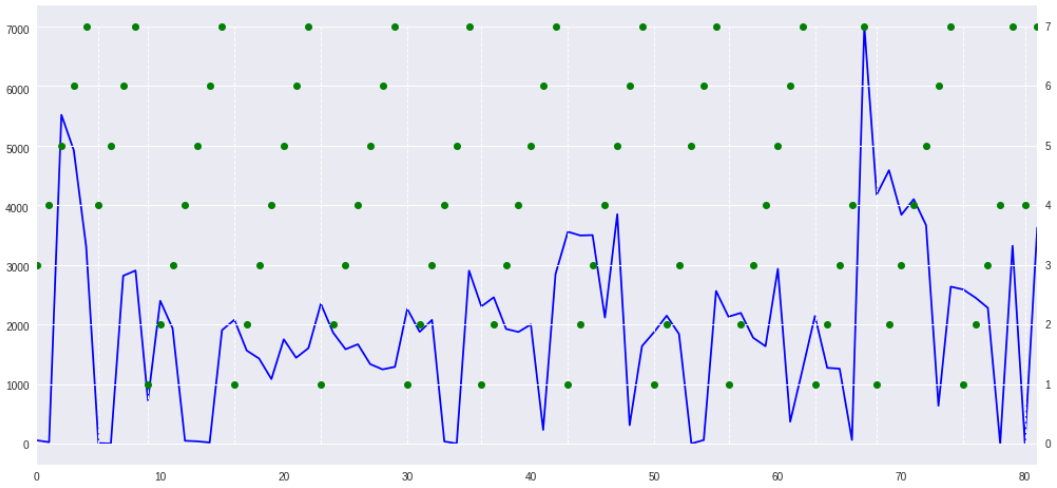
随便找一个时间段的数据画下趋势:
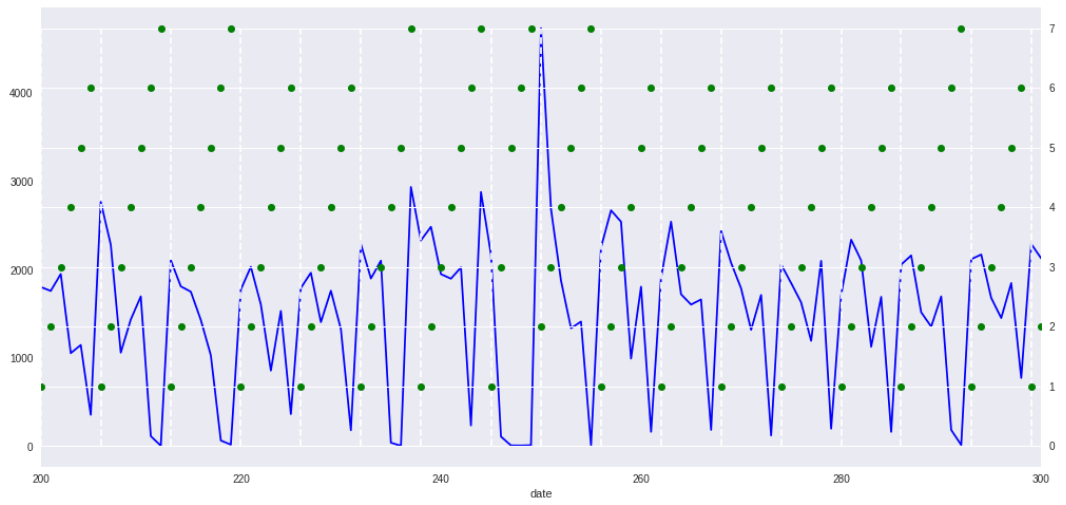
其中蓝色线是当日上牌量,绿色点是当天的星期数,白色竖线是划分开每一周的时间区间。
到这里就不难看出了,每一周的周末都会出现一个明显的谷值,而工作日时间的上牌量则比较不确定,但是变化趋势跟平均值大致是一致的。上牌量与星期数有明显的相关性
此外,由于day_of_week基本连续,所以可以很容易的判断出新一周的开始,而根据星期数的空缺值的填充,也能得到修正后的date字段(训练集给的date字段并不会因为日期的空缺而有相应的跳跃)。于是第一个模型就诞生了:以修正后的date字段和day_of_week的one_hot作为输入特征,直接选用线性回归模型(当时考虑到特征实在太少了,而适合做回归问题的模型我暂时只知道这个)。提交到线上得到的误差是908072。
既然每一天的上牌量波动比较大,那按周统计的上牌量就没那么大了吧?而预测问题自然不可能拿当周的总上牌量做特征,于是我想试着用前一周的上牌量作为特征输入。然而测试集要预测的时间并不止一两周,所以我就打算一周一周的预测:先预测出一周的上牌量,然后将预测出的上牌量作为一个特征输入到下一周的模型预测当中。出来的结果误差瞬间飙多了7w,于是这种思路就果断放弃掉了。
后来在跟师兄的聊天中,师兄评价说“你用一个不确定的中间特征去预测一个不确定的值,好比本来都是80%的准确率,一叠加就只剩64%的了”,这么想想确实有道理,于是后面的模型思路都是直接预测目标值。
前面漏了说明一点,我本地验证模型的时候是用前三分之二的训练数据去预测后三分之一的数据,赛题说明里说了训练集是三年数据,三分之二就是两年,当时觉得两年以前的上牌量间隔的时间太久,对当前预测的日期帮助不大,所以提交到线上的模型一直都是只用了后两年的数据进行训练的。后来在跟队友交流的过程中,采取他们的建议换用了全部数据去训练模型,最终线上误差降低了4w,达到866352。
重磅炸弹:日期还原
显然目前的特征远远不够(个人觉得特征太少是这次比赛拉不开差距的重要原因),于是我开始继续观察数据集,然后星期天的上牌量情况就吸引了我的注意,贴一段样本数据给大家看看:
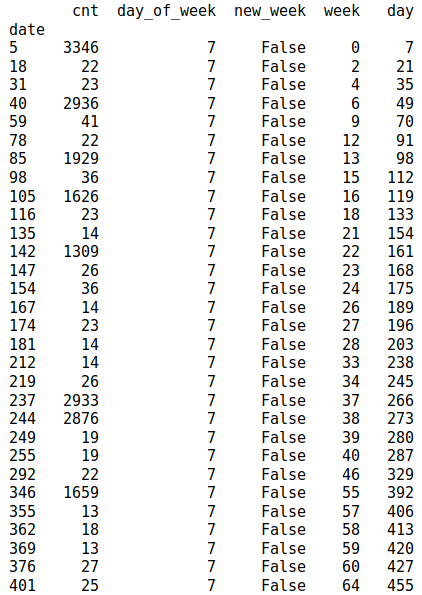
前面的分析已经知道了上牌量在周末休息的时候会有一个明显的谷值,周日的上牌量也大多都在100以下。然而中间这些反常的上千的上牌量又是怎么回事?我的猜测是那几天调休,周日上班,所以上牌量高。接下来绘制了异常数据当周的上牌量趋势,基本证明了猜想:周末高的数据,在周一至周五会出现另外的谷值。
一年当中会调休的时间无非就几个节假日,而几个节假日之间的间隔并不均衡,有没有可能通过节假日去定位出每个样本的真实日期??赛制里面提到整个赛季共用到5年的数据,那就先假定日期是从12年开始的。后来在尝试日期对齐的过程,发现了另一个更明显的特征:日期的连续缺失。
通常来说,数据集中平均每一周会缺失一天的数据,但有些时候却会连续缺失三四天数据。全年之中超过3天的假期只有国庆和春节,一筛选连续缺失超过4天的样本数据,很快就把日期全部对应上了,甚至还发现测试集A的第一条跟训练集最后一条数据的日期相同(于是后来每次提交预测前都用训练集的数据替代掉了testA的第一条预测结果)。再check一下测试集A跟测试集B的数据日期还原,完美对应!
本地比赛是允许使用外部数据集的,既然还原了日期,那么就有很多特征可以挖了。首要的第一件事,就是去网上找一个工作日跟节假日标记的API,将假日类型作为一个特征输入到模型里面。实际上我找到的API是划分了三种假日类型的:工作日/休息日/节假日,one-hot之后就是三个特征,再加上真实日期的年/月/日特征,以及月份的one-hot(当时真的是想到什么就加什么特征)。提交到线上的结果,误差瞬间降到了636030,此时的成绩已经在十名以内。
继续找特征,下图是根据每周上牌量统计出来的趋势图:
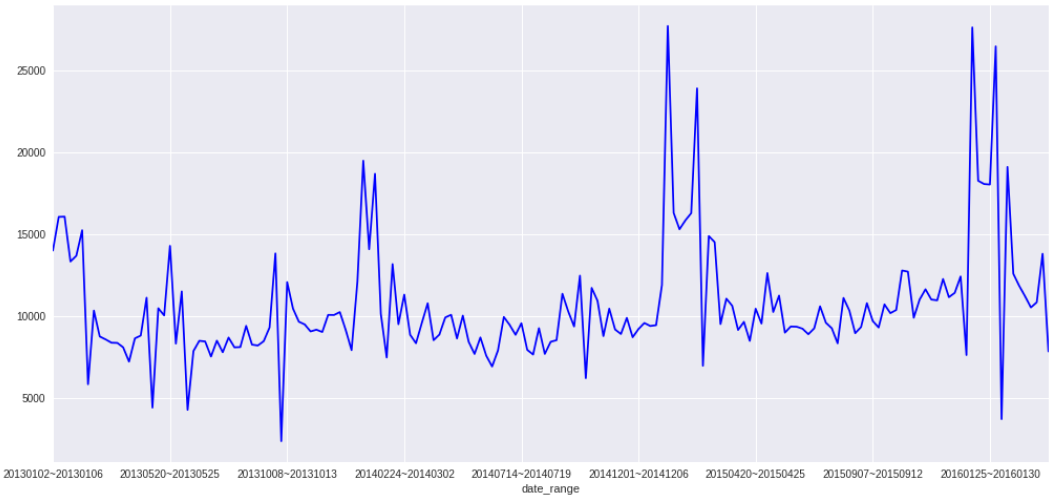
将日期维度放大,发现每年元旦后/春节前都会有两个明显的峰值,而春节后会有一个谷值(后来发现这个谷值是因为大多数春节后的第一周都没几个工作日时间),然后立马又是一个小高峰。再次切换为日统计量的曲线图,粗略判断是元旦后的2~5个工作日涨幅明显,春节前9个工作日上牌量偏高,春节后5个工作了的上牌量偏高,并且春节前的最后一个工作日上牌量会很低。我想到了两种为这些特殊日子标注的方法:一种是设定一个天数阈值,离假期最近那几天都标记为1;另一种是按照距离假期的天数赋权重,离假期越远权重越低,不受假期影响的全部为0。在本地的时候分析不出哪种方法比较好,于是就两种都用了。后面又用同样的方法分析了国庆节前后的上牌量特征,考虑到此时模型的特征已经有点多了,为了避免算法发散,又将线性回归改成了带L2正则项的岭回归。最终模型的特征列表如下:
基于周数和星期的修正日期
星期的one-hot特征
真实日期的年月日及月份的one-hot特征,一年中的第几天
是否工作日/休息日/节假日
元旦后5个工作日/春节前9个工作日/春节前1个工作日/春节后5个工作日/国庆后1个工作日的标记,元旦后5个工作日的修正权重
最终线上误差降到了554095,排名第7。这是我这次比赛期间个人单模型的最好成绩。
艰难的瓶颈期
A榜后期
以前听说xgboost模型特别的火,拿来预测分类很好用,也可以用来预测回归问题,于是决定尝试下用树模型做做。一模一样的特征,参数照着网上博客说的取值范围胡乱调了下(顺便附上当时的xgb参数设置),在本地一跑,结果居然只有35w左右的误差(之前岭回归在本地跑出来的误差大约42w)。一阵狂喜,立马将模型提交到线上,然而第二天却发现线上误差是556770,比之前的岭回归还高了2k。又尝试调了好几次模型参数和节假日特征的阈值,本地误差越来越低,线上误差却越来越高。怀疑是过拟合,却始终没有好的解决办法。
随便调的xgb参数:
‘objective’: ‘reg:linear’,
‘eval_metric’:’rmse’,
‘eta’: 0.4,
‘gamma’: 1400,
‘max_depth’: 5,
‘num_boost_round’: 10
找师兄取经,提到线上线下的数据分布不一致也可能导致误差差异过大。于是改进了验证集的划分方式:测试集A是从16年4月份开始预测的,本地验证集就从15年4月开始。然后又设置了滑动窗:用15年1月前2年数据预测15年1月后一年数据/15年2月前2年数据预测15年2月后一年数据/15年3月前2年数据预测15年3月后一年数据……以此类推。采用新的验证集划分方式后,线下误差依旧跟线上差距很大,但是也让我发现了一些问题:从15年1月到4月预测出的这四组数据误差波动很大(误差最大37w最小23w),我的模型似乎对预测集的开始时间很敏感。
随后我又重新在岭回归模型上做了滑动窗的检验,发现岭回归的误差虽然波动也大,但没有xgb那么离谱(但是线上线下误差的差距同样很大)。后来又绘制了偏差曲线(类似下图那样的),发现两个模型的曲线形状基本一致,但xgb的偏差波动比岭回归要大一些,尤其是在高偏差的数据上,xgb要偏离得更加离谱。考虑到评判标准采用的是均方误差,大偏差的数据平方后很容易就会把误差放的很大,这么算下来波动没那么大的岭回归表现可能要更好。此外就是临近元旦和春节的1月跟2月误差波动明显比其他月份来的明显。
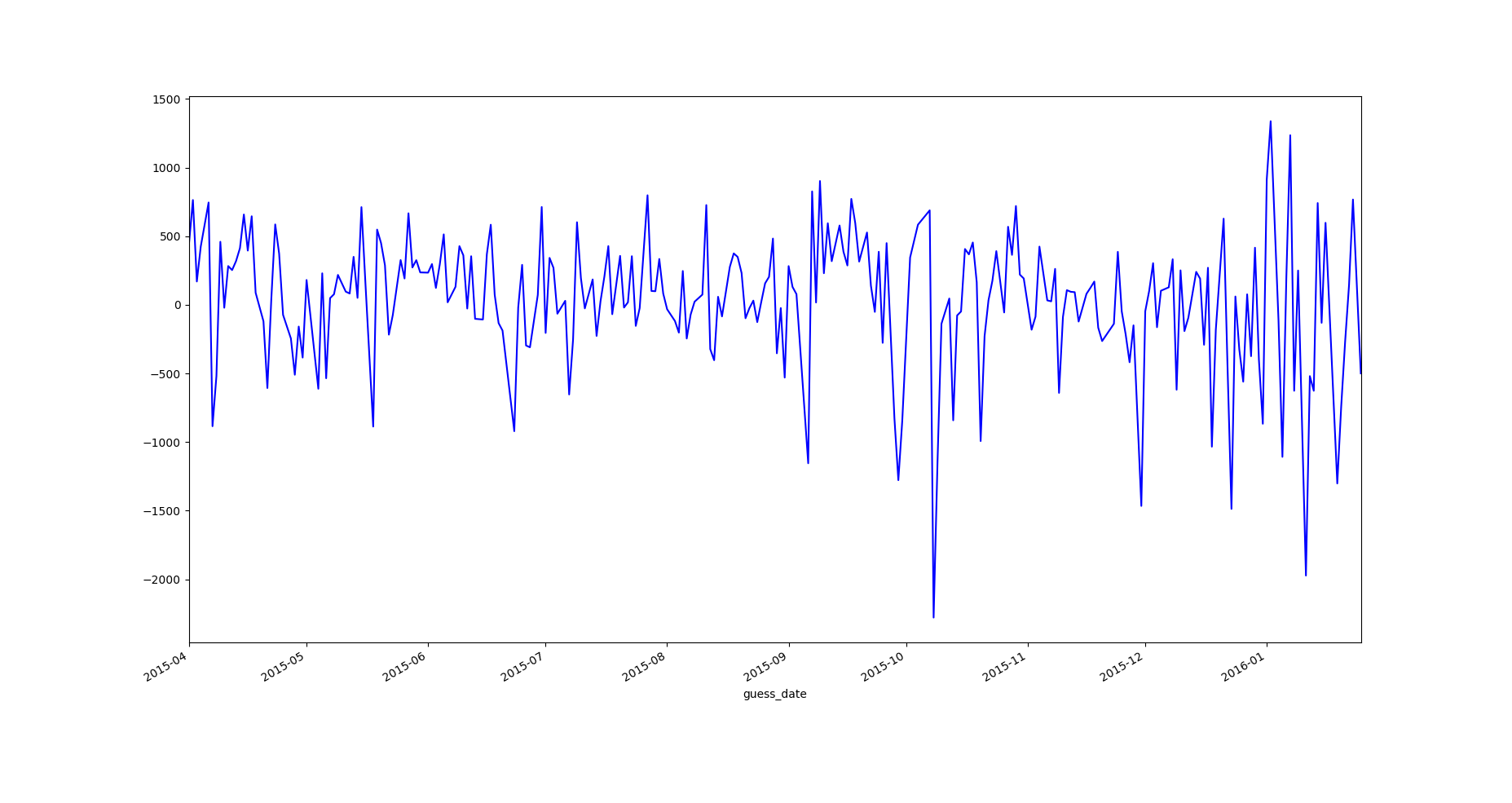
既然对误差贡献大的是那些大偏差的数据,那接下来的目标就是想办法降低高偏差数据的偏差值,至少不要偏离得那么离谱。于是又继续开始了找特征的过程,从目前的数据信息上始终观察不出高偏差数据的共同点(除了大都发生在12月~3月以外),于是开始考虑找外部数据。一个是隔壁车辆销售量比赛的月销售量数据,另一个是天气(当时的猜测是恶劣的天气上牌数可能会降低),其中天气数据是写了个爬虫从天气网历史天气上爬下来的:后期的观察发现,天气跟上牌量几乎没有任何对应关系,无论是否天气恶劣(后来队友告诉我上牌是要提前预约的)。而销售量看似确实是有些关系,但是放进模型后,误差依旧是只增不减。
之前有队友提出一个idea:就是将5个品牌拆分开分别训练5个模型,最后再将模型预测结果相加。这种方式后来我也尝试了,但是线下误差变得更大。仔细比对预测出来的数据集,我发现训练集中并不是每一天都有5个品牌的数据,有些天可能只有一两个品牌,测试集想必也是如此。而拆分成5个模型后,相当于每一天都有来自5个品牌的数据,那么势必有些天的上牌量总数要比真实值更高。此外,也并非所有的品牌都有休息日和节假日的数据,缺少相应特殊时间的数据,导致有些品牌在本应该上牌量很少的日期依旧保持了工作日的高上牌量,这也是误差来源。
之后又胡乱的加了一些特征,比如年月拼接/月日拼接,但是都没有帮助。此时另外两个队友用我还原的日期特征已经分别将模型做到了第2名和第10+名,而我的成绩已经掉出了前30。
模型融合
A榜的最后两天,我们决定组队融合模型。分别尝试了blending加权平均和stacking两种方法。
blending的权值参考以前大佬们的经验,对线上排名求倒数后再归一化,具体计算公式如下:
这么按排名算下来,我的权重只有可怜的0.04。但融合的结果还是不错的,原先排名最高的队友误差是45w左右,融合后的误差是435387,跃居榜首(虽然一进B榜就被踢下来了)。此时我也大概了解了两位队友的模型情况:
排名前3的队友用的线性回归,特征是:
‘day’,’day_of_week_1’,’day_of_week_2’,’day_of_week_3’,’day_of_week_4’,’day_of_week_5’,’day_of_week_6’,’day_of_week_7’,
‘national_day’,’after_national_day’,’chinese_new_year’,’new_year_day’,’after_new_year_day’,’after_chinese_new_year’,’labor_day’,’mid_autumn_festival’,
‘day_type_0’,’day_type_1’,’day_type_2’
排名10+的队友用的也是线性回归,特征是:
‘week_scaled’, ‘date_year_scaled’, ‘sale_quantity_scaled’,
‘day_of_week_1’, ‘day_of_week_2’, ‘day_of_week_3’,’day_of_week_4’, ‘day_of_week_5’, ‘day_of_week_6’, ‘day_of_week_7’,
‘date_property_0’, ‘date_property_1’, ‘date_property_2’,
‘date_month_1’, ‘date_month_2’, ‘date_month_3’, ‘date_month_4’, ‘date_month_5’, ‘date_month_6’, ‘date_month_7’,’date_month_8’, ‘date_month_9’, ‘date_month_10’, ‘date_month_11’, ‘date_month_12’,
‘dividedMonth_late’, ‘dividedMonth_early’,
‘after_restday_one’, ‘after_holiday_one’,
‘is_holi_restday’, ‘is_newYearDay’, ‘isHolidayWeekend’, ‘isPureWeekend’
还打听了他们线上线下误差的情况,排名最高的队友线下误差比线上少5w,排名第二的相差15w不到,然而我差了30+w。看到成绩最好的队友模型竟然只有这么点特征,我开始怀疑我的特征是不是加多了。
模型融合第二天,我们决定尝试stacking方式融合。训练第二层模型所需的训练集和测试集的代码参考的是网上那个传播甚广的get_oof代码:
ntrain=train.shape[0] ## 891
ntest=test.shape[0] ## 418
kf=KFold(n_splits=5,random_state=2017)
def get_oof(clf,x_train,y_train,x_test):
oof_train=np.zeros((ntrain,)) ##shape为(ntrain,)表示只有一维 891*1
oof_test=np.zeros((ntest,)) ## 418*1
oof_test_skf=np.empty((5,ntest)) ## 5*418
for i,(train_index,test_index) in enumerate(kf.split(x_train)):
kf_x_train=x_train[train_index] ## (891/5 *4)*7 故shape:(712*7)
kf_y_train=y_train[train_index] ## 712*1
kf_x_test=x_train[test_index] ## 179*7
clf.train(kf_x_train,kf_y_train)
oof_train[test_index]=clf.predict(kf_x_test)
oof_test_skf[i,:]=clf.predict(x_test)
oof_test[:]=oof_test_skf.mean(axis=0)
return oof_train.reshape(-1,1),oof_test.reshape(-1,1)
stacking第二层选用的模型是岭回归,参考网上的经验,第二层除了输入各模型的预测值,还可以输入一些强特征。于是最终选用的特征有:三个单模型的预测值,和三种假日类型的one-hot值,然而提交后线上的误差反而升高到了530707。后来有个师兄说,stacking适合单模型之间差异较大的模型融合,像我们这样都是线性回归特征也差不多的,直接加权平均可能会来得更有效。于是stacking暂时就被弃了。
A榜结束后会公布A榜答案,是为了方便选手用来训练预测再下一年的B榜数据,同时也给我们提供了一个校验A榜误差来源的绝佳机会。通过几次特征的删减测试,我也终于找到了A榜的误差来源:那些非线性相关的日期特征坏了整个模型的预测结果!在大刀阔斧的删掉一批无线性相关性以及相关性不强的特征后,误差瞬间降到了46w附近。原来特征真的不是越多越好的!
此外就是分析绘制出来的testA的预测偏差图,17年的1月2月直接雪崩,粗略测试了下,这两个月起码贡献了10w的误差值= =。
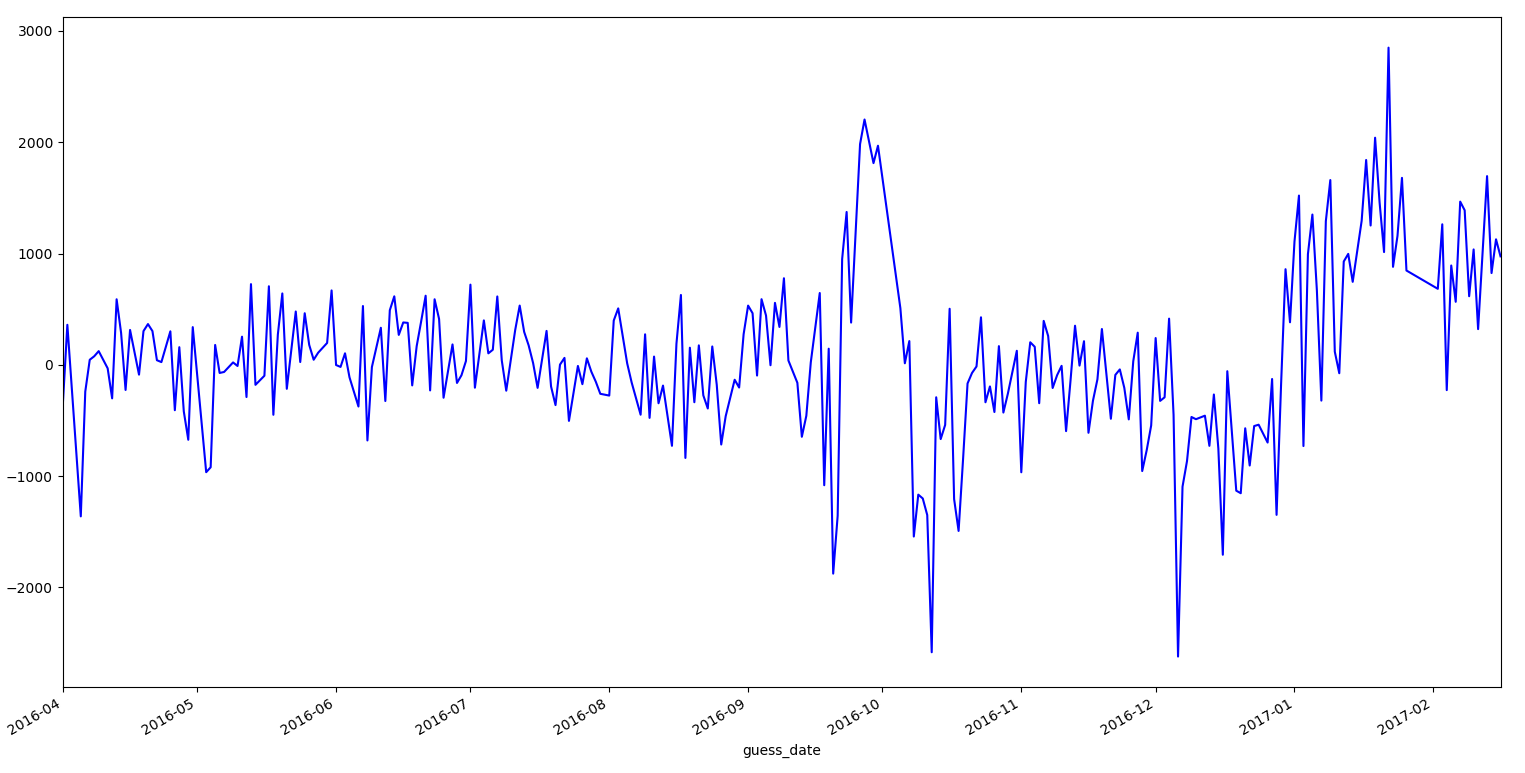
立刻百度查找16年10月和17年初的异常原因。得知每年9月下旬盐城会有国际车展节,该展会似乎从15年开始收到比较大的关注。但是依然没法解释为何16年车展节的第一周有大量的上牌量,而第二周(也是国庆节前一周)上牌量又爆低,于是10月的误差异常只好先放在了一边。
至于17年初上牌量预测值整体偏高的原因,我在网上搜到了一篇分析报道的销售量统计曲线图:
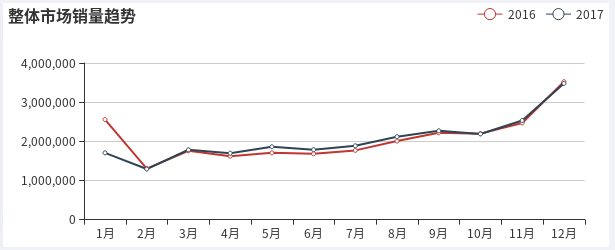
可以看到17年1月份的销售量比16年同期降低了很多,所以17年1月至2月的上牌量预测才会整体偏高。这么看来,销售量与上牌量确实是有比较大的相关性。而且还能发现销售量也有月份的旺季跟淡季,并且往年同期的销售量(同比)要比上月的销售量(环比)更有参考价值。于是很自然的,销售量特征重新被我运用到了模型当中。大概是先前那些影响模型的无用特征已经被清除掉了,这次再加入销售量特征,模型很快就有了进一步的提升。于是最终岭回归模型的特征如下:
岭回归初赛B榜特征:
星期1/2/3/4/6的onehot标记
月份1/2/6/7/8/11/12的onehot标记
节假日类型0/1/2的onehot标记(第三方接口)
本月销售量(取自零售量比赛数据,其中17年11月数据根据网上的16年同期增长比估算)
元旦后5个工作日,元旦后工作日的修正权重
春节前9个工作日/春节前5个工作日/春节前1个工作日/春节后3个工作日
五一后1个工作日
国庆后1个工作日
线下测得的原A榜误差:约42w
队友说既然我的A榜误差降下来了,那就重新调整下融合模型的加权比例。然而大概是被之前线上线下测得的超大偏差弄得有些心里阴影,那时我实在没这个胆量按现在的这个误差计算权重(毕竟算下来可能就是原来10倍的权重了),所以B榜继续沿用了A榜的权重比例。第一天提交的融合模型误差是42w多,后来经过对融合模型的预测结果排查,发现NO.1的队友把B榜国庆节的假日标记弄错了,导致有两个数据出现极大的预测偏差,于是赶紧又修正了bug提交,第二天B榜的最终成绩误差是414812。而那天由于众所周知的有同学在技术圈公布了真实日期的还原方案,导致第二天的B榜排名出现极大变动,于是我们初赛的最终成绩定格在了第8名。
复赛阶段
诡异的A榜
复赛的数据集那天并没有按时公布,一直拖到了差不多下午6点才公开,虽然相应的第二天的评测时间也推迟到了下午4点,但还不太熟悉编程的队友将第一天提交评测的重任交到了我手上。
首先还原真实日期,观察各品牌上牌量规律,基本上跟初赛特点一致。主要的关注到的不同点大概有以下几点:
- 各个品牌上牌量的均值不同,节假日前后上牌量的变化趋势也略有不同。
- 品牌5从14年7月才开始有数据,而其他品牌都是从13年1月开始
- 双休日跟节假日数据略少,有些品牌几乎没有节假日的数据
- A榜预测的时间从16年5月至16年10月,B榜则是从16年10月至17年11月底,14个月的时间跨度明显难度更大。
考虑到要给B榜预测做准备,线下一律划分了一年长度的验证集。有了初赛的特征教训,这次复赛我没有再乱改特征,基本沿用了初赛的特征,仅仅是补全了星期跟月份的one-hot特征,以及对第三方API爬下来的假日类型进行了纠错处理。在模型训练上则尝试了两种方式:一种是将10个品牌合起来训练一个模型,只是另外加多10个品牌的onehot特征;另一种则是将10个品牌拆分成10个模型分开训练预测。本地测试的效果发现拆分成10个模型要好很多(预测一年的误差大约是4.3w),并且从输出的回归系数上看,10个品牌对各个特征的敏感度也各不相同,所以提交到线上的是拆分成10个模型的岭回归,误差是34835。
然而复赛毕竟是拆开品牌预测的,样本规律没有初赛那么稳定,尤其是品牌5的数据缺失严重,在岭回归里难免会样本量不足。如果10个品牌之间的部分数据特征能共享就好了。抱着这样的想法,我又重新捡回了xgboost模型,果然xgb模型将10个品牌合在一起训练的误差要比拆分成10个模型低,而且线下测得的误差与岭回归差距不大,正好符合预期。于是决定继续折腾xgb,将节假日前后的工作日标记一律换成递减权重(因为树模型能够自动判断合适的权重阈值),又将历史上牌量的均值跟中位数考虑进来,总的特征列表如下:
xgboost模型特征列表: 星期1~7的onehot标记
月份1~12的onehot标记
节假日类型0/1/2的onehot标记
历史同假日类型的上牌量中位数/平均数
历史同月份的上排量中位数/平均数
是否是周日且非工作日
本月销售量/上个月销售量(取自零售量比赛数据)
元旦前5个工作日权重,元旦后5个工作日权重
春节前9个工作日权重,春节后5个工作日权重
五一后1个工作日权重
国庆前5个工作日权重,国庆后3个工作日权重
此外在模型调参上也翻看了网上很多的调参技巧博客,将步长调低,迭代次数根据CV验证集确定,其他参数按强弱依次选取。于是最后xgb模型参数如下:
采用“科学调参”后的xgb参数:
‘objective’: ‘reg:linear’,
‘eval_metric’:’rmse’,
‘silent’: True,
‘eta’: 0.05,
‘max_depth’: 7,
‘gamma’: 300,
‘subsample’:1,
‘colsample_bytree’: 0.9
‘num_boost_round’: 1000
‘early_stopping_rounds’: 3
除此之外,为了避免xgb过度拟合那些异常偏高的数据,还做了一点数据清洗:将前后7天内出现异常拔高的数据删除了(除了节假日前后相关的日期)
由于组队后提交机会有限,直到第5天才把上面这个模型结果提交,线上误差是39036,离岭回归还有一段距离,但其实在本地验证时xgb的误差要比岭回归低3000左右,估计xgb还是有点过拟合了。但其他两个队友却碰到了点麻烦,他们本地的误差无论如何都降不到5w以下,无奈提交到线上,特征少的队友误差是34356,跟我提交的岭回归模型差不多;特征多的误差则是去到了4.8w。看到群上有人提到prophet模型可以预测趋势,于是那个伙伴就转去研究prophet了。
然而此时复赛中期的A榜却出现了一种诡异的情况,大量的队伍误差降到3w甚至2w以下,钉钉群里也炸开了锅,很多人说无论怎么试误差最低只能调到3w2,怀疑前面的队伍是不是用了初赛公布的数据答案,毕竟经过数据对比可以发现,复赛中有两个品牌与初赛是相同的,另外初赛提供的当日总上牌量也是一个比较强的特征。
随后官方终于出了一条补充说明:为还原真实场景需求,除日期和假日外的未来数据,皆不可使用。组委会将在复赛结束后,对入围团队的算法进行审核,如发现将影响获得决赛资格。
作为第一次参加比赛的萌新,我们对所谓的“未来数据”的定义产生了困惑,这个未来到底是相对于当前预测的样本数据,还是相对于整个测试集?群上有一些有比赛经验的大佬说是相对于整个测试集的,那就意味着销售量特征基本不能用。我尝试着将销售量特征剔除,发现误差瞬间涨了2w,但如果只是剔除掉本月销售量,改用上月销售量和上月销售量同比,那么误差变动就不会很大。怀着一点侥幸心理,我按照“相对当前预测样本”的意思去理解,重新调整了模型特征和参数:
xgb模型特征: 星期1~7的onehot标记
月份1~12的onehot标记
节假日类型0/1/2的onehot标记
是否是周日且非工作日
上个月销售量/上个月销售量的同比(取自零售量比赛数据)
元旦前5个工作日权重,元旦后5个工作日权重
春节前9个工作日权重,春节后5个工作日权重
五一后1个工作日权重
国庆前5个工作日权重,国庆后3个工作日权重
xgb模型参数: ‘objective’: ‘reg:linear’,
‘eval_metric’:’rmse’,
‘silent’: True,
‘eta’: 0.08,
‘max_depth’: 5,
‘gamma’: 200,
‘min_child_weight’: 14
‘colsample_bytree’: 0.9
‘num_boost_round’: 1500
‘early_stopping_rounds’: 30
‘nfold’: 10
其中历史上牌量特征经测试发现会使部分时间的预测值拔高严重,故删去。而max_depth/gamma/min_child_weight参数改用10折网格搜索分别确定最佳值,此外模型也按照假日类型分成了3批进行训练和预测。最终线上误差是37033。
遗憾的B榜
A榜的时候我们队伍并没有进行模型融合,直到B榜才开始。当A榜答案公布后,几个队友便约定了每人在线下各自训练模型,预测15年10月至16年10月15日(即手头能拿到的所有训练数据),然后用这一年多时间的线下误差决定三个模型的融合权重。由于xgb的模型最终依旧没能超过岭回归的结果,所以我提交的依旧是岭回归模型,具体特征如下:
星期1~6的onehot标记
月份1~12的onehot标记
节假日类型0/1/2的onehot标记
周日休息日标记
上月销售量,上月销售量同比
元旦前3天,元旦前5天,元旦后1天,元旦后3个工作日,元旦后5个工作日,元旦后权重
春节前9个工作日/春节前5个工作日/春节前1个工作日/春节后3个工作日
五一后1个工作日
国庆后1个工作日,国庆前3天
训练前依旧是做了数据清洗除去了异常拔高的数据,另外模型除了按品牌拆分还按工作日和休息日拆分,总共是10*2=20个模型,而节假日的预测值则直接用各品牌节假日的历史中位数代替。最终线下误差是4.9w
另外两个同伴,特征少的依旧用的线性回归,误差5w;另一个则是用刚研究的prophet,4.8w。两人均没有使用销售量特征(就我在玩火)。误差接近,于是模型融合直接平均相加了。提交后的线上误差是34782,排名第6。
最后一天,我终于还是趁着工作人员在群上的期间去确认了“未来数据”的定义,被告知不能使用testB时间开始的数据均不能使用。那么我的模型误差就是6w9,基本是废了。后来有队友说品牌8头1.5年的数据规律与后面几年差距很大,问我们要不要考虑从训练集删除。这么一来我才认真的去研究了品牌8的数据曲线,发现真的问题很大,之前没发现这个问题简直是重大失误:
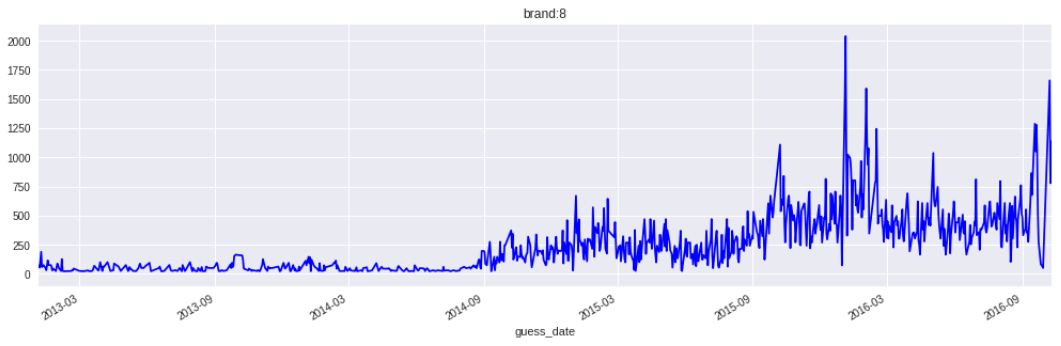
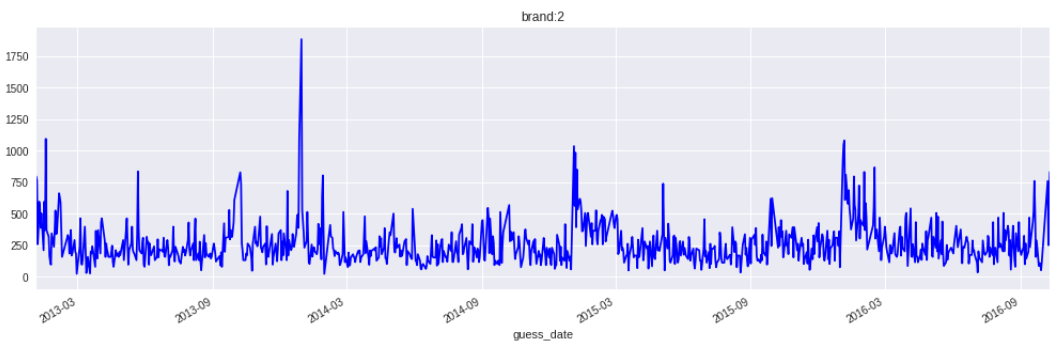
不仅是品牌8,好几个品牌初期的数据规律也和后几年的数据不太一致。于是又开始了大幅度的砍数据。然而岭回归模型毕竟是要分品牌预测,数据不能删得太多,反倒是不分品牌的xgb模型在大幅的删减数据后,误差逐渐降回了5w3。
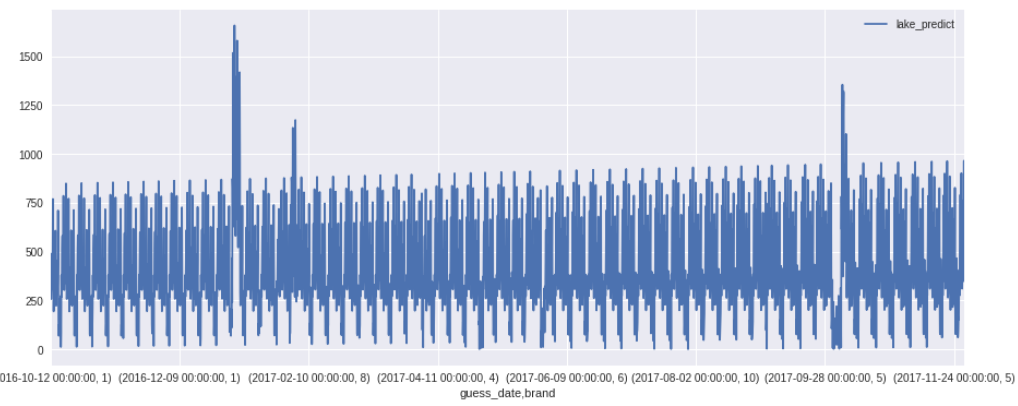
于此同时另一个用线性回归的队友通过砍掉前期的异常数据,本地误差降到了让我们瞠目结舌的4.2w。不过他的预测曲线却很有意思,这里贴下我们三个模型的预测曲线做个对比:
lake同志的曲线:
我们两的曲线:
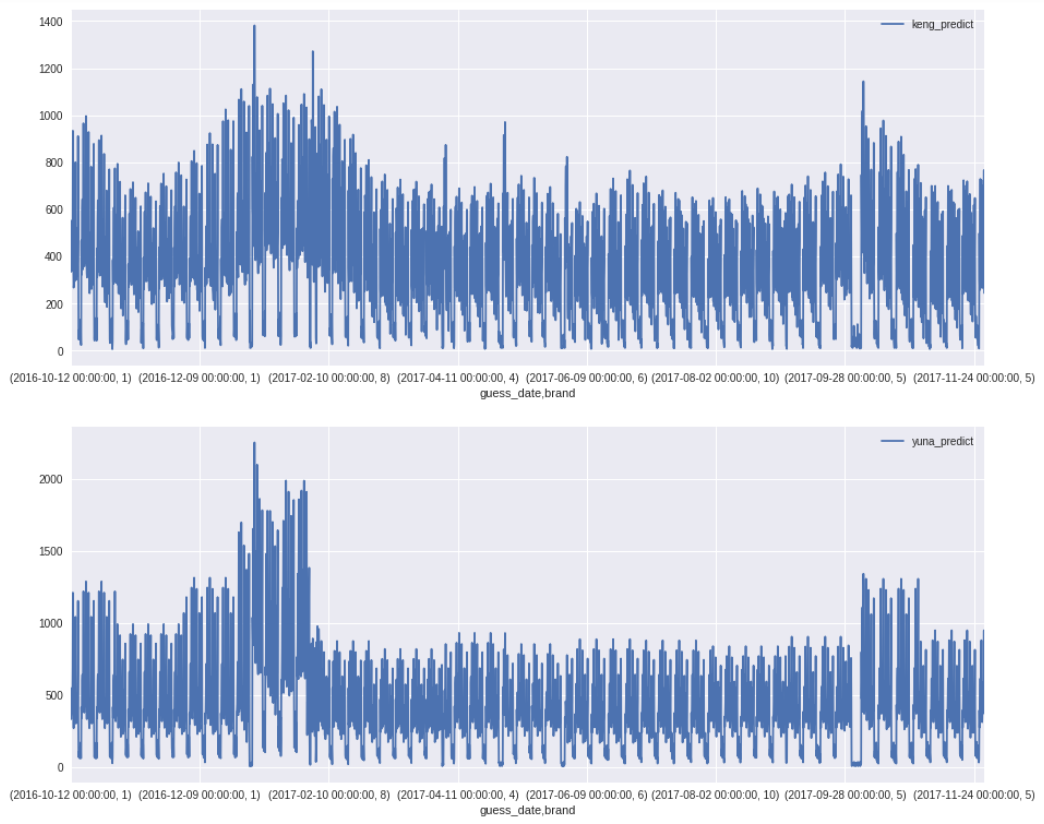
第一个模型的预测结果几乎就是一条的直线,只在1月份和10月份个别峰值点有些突变。不像另外两个的模型还看得出一些时间波动上的规律。然而就是这样一条递增的直线却能达到4.2w误差,难怪有师兄说“时间序列问题有时还不如直接用平均值去预测。”
此外融合模型的权值也做了些变动,不同品牌按照各自单模型的品牌误差分配不同的模型权重。最后预测出来的数据看起来还算合理,可惜第二天的结果并没有提升,反倒是后面有一堆的队伍提升了,于是直接被挤到了17名,比赛结束。