赛题介绍
给定广告点击相关的用户(user)、广告商品(ad)、检索词(query)、上下文内容(context)、商店(shop)等信息的条件下预测广告产生购买行为的概率(pCVR)。其中初赛预测的是普通日期的广告转化率,复赛预测的是特殊日期的广告转化率。
最终成绩:复赛48名
赛题分析
-
本赛题的正负样本比例极度不均衡,但是因为采用的是logloss评价函数,不适合抽样更改训练数据集的正负样本比,同样的有些模型的参数(比如xgb的scale_pos_weight)也是不宜用的,这些在模型的官方文档上也有说明。
-
单一用户的记录太少,很多用户在整个数据集中都只有一条记录,因此用户维度的特征比较难挖掘,相反商品维度的特征会更有帮助一些。
-
初赛与复赛由于预测的日期属性不同,造成数据分布上很大的变化。原本初赛的特征方法和模型构建方法仅仅是对复赛有一定参考,但并不完全适用,因此在同样只有2周时间的情况下,复赛的难度就变大了不少。
-
复赛提供了31号至7号共8天的数据,其中7号为特殊日期。通过日转化率均值分析可以看出前4天交易率比较稳定。4号开始受7号特殊日期影响,交易率越来越低。7号暴涨。从各个特征的数据分析上也可以看出,7号当天的统计规律与前几天并不一致,因此训练时加入太多普通日期可能会影响模型学习的准确性。
date is_trade 2018-08-31 0.012838 2018-09-01 0.013609 2018-09-02 0.013290 2018-09-03 0.012378 2018-09-04 0.011367 2018-09-05 0.009772 2018-09-06 0.005498 2018-09-07 0.046089 -
从每天的小时转化率曲线上分析,虽然日转化率的均值不一样,但是在24小时上的转化率走势上基本保持一致。7号前半天的曲线走势也仅仅是0点附近的走势与其他日期不一致,因此大概可以从普通日期的走势上估计出7号后半天每个小时的转化率。
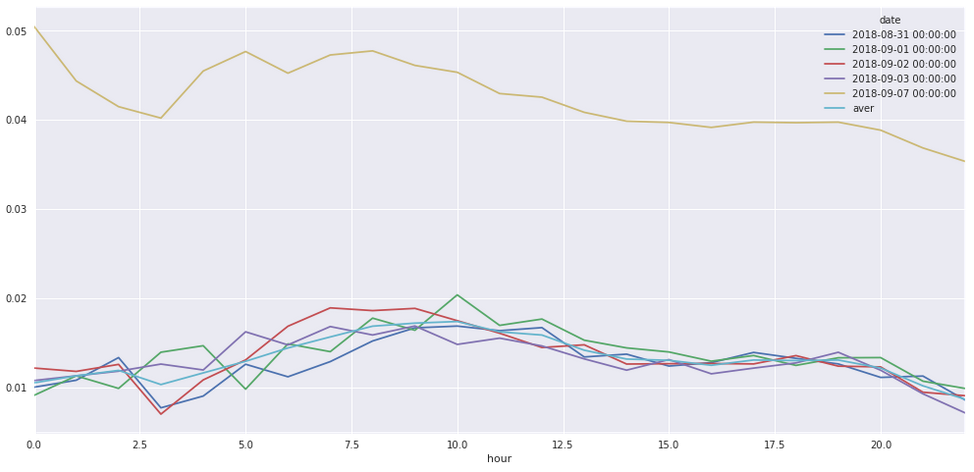
其实还尝试过根据往年双十一的网上新闻评估销量变化趋势,由此换算7号后半天各小时的转化率趋势,然而提交到线上测试的效果并不好。
-
经过测试,在训练数据集中加入一部分普通日期(4号之前)的数据,可以比较好的学习到7号后半天的转化率趋势,但是会对树模型特征的分裂选择上造成影响。而如果只用7号训练,再手动调节各小时的转化率,则普遍可以达到比前一种模型更优的成绩。因此复赛我们主要是采用后一种模型训练方式。
特征工程
主要从以下几个方面的思路提取特征:
-
基础特征:包括赛题提供的原始数据,小时数,各级商品类目的拆分,商品属性的拆分,上下文信息的拆分等。
- 单维度统计特征:包括商品、用户、店铺、类目、品牌等维度的点击率、交易率、转化率等统计特征,统计时长包括样本时间点以前的全部历史统计数据和样本前一天的滑窗统计数据。
- 对于用户维度,还统计了用户的行为特征如距离上次点击时间,距离下次点击时间,最近一小时点击频率等。
- 对于商品、店铺等维度,还统计了平均用户年龄,平均销量、收藏量,用户性别占比等,以及跟同类在价格、销量、年龄等方面的对比。
- 交叉维度统计特征:例如从用户和类别维度的行为统计,用户和商品维度的行为统计,商品和年龄维度,商品和性别维度,店铺和年龄,店铺和性别,品牌和年龄,品牌和性别等各维度的交叉统计。
特征处理方式上,主要有以下几点考虑:
-
贝叶斯平滑:对所有符合B分布规律的比率特征,进行贝叶斯平滑处理。由于历史统计特征统计的是样本时间点以前,因此前几天的样本统计量小,其他一些样本的统计量大,通过贝叶斯对整体做平滑,可以减小统计量小导致统计比率不精确的差异问题。在贝叶斯的参数求解上,采用的是矩估计法求解。
-
对于小时转化率特征,由于7号下午是待预测数据,因此7号下午的转化率通过前4天的小时转化率均值,再加上与7号上午的转化率差距估算求得。
-
关于上下文搜索信息与商品信息匹配程度的特征提取,有尝试过判断搜索类别与商品类别是否吻合,以及求商品属性与搜索关键词属性的杰卡森相似度等方式,但是提出来的特征效果都不太好,我们认为这块搜索匹配程度应该是比较重要的特征,希望其他队伍能提供比较好的方案。
特征选择
我主要是采用人工组合和人工筛选的方式来筛选特征,具体做法如下:
-
计算特征与label之间的皮尔森相关系数(但是该系数仅仅是反映线性相关性)
-
用seaborn绘制特征值与label之间相关曲线,曲线走势比较明显的保留作候选特征,曲线走势杂乱且皮尔森相关性太低的剔除
-
wrapper法:将候选特征逐步丢入模型训练,通过线下预测结果的好坏决定特征的去留。该方式的得到的结果比较准确,但因为要不断重复训练模型,在复赛暴涨的数据量下也非常耗时。
模型构建
这次比赛的最终模型主要是选用了xgb,当然我们也尝试了一些其他模型,然而效果不理想没采用:
-
xgboost特殊日期模型:剔除掉特征工程中过于稀疏的类别特征(如商品id、品牌id、类目id等),仅用7号上午的数据训练,但这样预测出来的7号下午的转化率走势是不正常的(随着小时数增长,平均转化率也直线上升)。因此对于预测出来的7号下午的结果,我们还按12个小时分别手动调整了预测结果的转化率均值,使得测试集12个小时的转化率趋势与训练集普通日期的转化率趋势相吻合。最后再整体调了下均值使得与线上测试集的均值相符(关于如何得知线上测试集的标签均值可以关注下我的github博客)
-
xgboost普通+特殊日期模型:最开始的时候,我尝试的是30%的普通日期+7号上午的全部数据作为模型训练集。A榜的时候,这样的训练出来的模型在预测7号下午时可以很好的拟合7号后半天的小时转化率趋势,而且预测结果的均值基本与线上测试集的均值一致。然而后来发现采用前一种只用特殊日期训练,再手动拟合趋势的模型效果普遍比这个模型的效果要好(线上误差从0.14517降到0.14449),所以这个模型就被弃用了。直到最后B榜模型融合时,为了加大模型之间的差异性,又采用了15%普通日期+7号上午数据作为训练集的方案,预测出来的模型本地误差比前一个模型要好一点点,但是并不能预测出转化率趋势,因此需要用上个模型的方法在后期对均值做手动调整。
-
lightgbm普通+特殊日期模型:lgb是一直到复赛最后,为了增加模型融合的差异性才引入的新模型,特征上直接沿用xgb模型的特征,结果处理方式与上述模型相同,预测出来的结果和平均误差也和xgb类似,不再多说。
-
模型融合:xgb模型总共是两个队友分别各自做的特征工程(期间偶尔一起交流探讨下特征),各自训练了一个xgb特殊日期模型和一个xgb普通+特殊日期模型。因此最终模型融合时,总共是2个xgb特殊日期模型 + 2个xgb普通/特殊日期模型 + 1个lgb普通/特殊日期模型。采用的是加权平均,比例则是参考线下检验误差确定。
其他一些没采用的模型情况:
-
ffm模型:选用的是C++接口的libffm包,自己在python封装生成训练数据文件的接口和调用命令行训练的接口。ffm的特点是在保留线性模型对稀疏特征友好的特性下,还自动做了特征之间的两两组合。因此ffm的特征尽量选取稀疏化的特征,如商品id、店铺id、类目id等。对于类别型特性进行onehot处理,对于非线性相关的连续型特征进行分桶后onehot,线性相关性明显的特征直接保留。初赛阶段ffm模型的最佳成绩是0.08192(同时期的xgb模型误差是0.08137),然而随着特征的增加,ffm的训练时间也越来越久,误差上也没有太多的突破,最后就放弃了。
-
fm模型:复赛时嫌ffm没有现成python接口,以及考虑到libffm包在实现上省略了一次项和常数项的问题,就换成了封装好现成python接口的pylibfm包(本来想选用训练速度更快的fastfm包的,然而fastfm好像并不是用logloss作为损失函数,也没有看到有参数定义损失函数,不敢冒险),选用pylibfm包后代码节俭了很多,然而训练时发现pylibfm是单线程的!这训练速度就更慢了,最后还不如直接用回ffm模型。
-
sgd模型:准确说是采用了随机梯度下降算法的逻辑回归,sklearn上的包名是SGDClassifier。训练得很快,特征提取方式上与ffm模型一致,然而误差始终比xgb高了0.001以上
-
lr模型:情况跟sgd模型差不多,不过训练速度还更慢一点
关于模型调参,主要是比赛前期在特征提取得比较多的时候,用网格搜索确认了一组参数。此后就一直沿用直至复赛B榜时,再用网格搜索重新调整了一次特征。另外一个细节就是在前期没做完特征工程时,模型的col_sample(特征抽样)参数一直设置的是1,目的是为了保证线下误差不受特征顺序的影响。
模型检验
初赛复赛数据分布不同,因此我选用的线下检验方式也不相同。
-
初赛的数据集是9月18日~9月24日,9月25日是线上测试集。线下检验时,是用3天作为训练集,第四天作为验证集,分别检验了22号、23号、24号三天的误差。用这三天的误差升降情况综合考虑模型的效果(有时候加入新的特征会出现有些天误差下降,有些天误差上升的情况)。线上预测时,则是用19~24号(因为18号没有历史统计部分的特征)6天的数据去训练模型,然后对25号进行预测。
-
复赛时7号是特殊日期,当天的数据分布与前几天不太一致,因此线下检验时,首先是从做完了特征工程的数据集中随机抽样30%数据来缩短训练时间,然后通过5折的交叉验证计算7号上午(只计算7号的)的预测误差。大概是由于复赛数据量比较大,本地交叉验证的误差基本跟线上保持了同升降(各个模型都保持了一致),为此节省了很多线上检验的机会。